Yihao LIU

| Google scholar | Github | XiaoHongShu |
I am a Research Scientist at the Shanghai Artificial Intelligence Laboratory, where I lead a team focusing on multimodal generation and understanding. I earned my Bachelor’s degree in 2018 and my Ph.D. in 2023, both from the University of Chinese Academy of Sciences (UCAS). During my doctoral studies, I was affiliated with the Shenzhen Institutes of Advanced Technology (SIAT), Chinese Academy of Sciences, under the supervision of Prof. Yu Qiao and Prof. Chao Dong. My research lies at the intersection of computer vision, generative modeling, and scientific intelligence, with particular emphasis on multimodal foundation models and image/video enhancement.
Throughout my student journey, I have been honored with prestigious awards, including the President’s Award of the Chinese Academy of Sciences, the Zhu Li Yue Hua Outstanding Doctoral Student Award, the CAS Excellent Youth League Member Award, the Beijing Outstanding Graduate Award, the SIAT President’s Innovation Award, as well as the CVMJ 2025 Best Paper Honorable Mention Award.
I have also excelled in multiple international and national competitions, such as 1st place in the PIRM 2018 Perceptual Image Super-Resolution Challenge, 1st place in the AIM 2020 Video Frame Interpolation Challenge, 2nd place in the NTIRE 2021 HDR Enhancement Challenge, 3rd place in the UDC 2020 Under-Display Camera Restoration Challenge. I serve as a reviewer for various top journals and conferences, including TPAMI, TIP, TCSVT, TMM, CVPR, ICCV, ECCV, NeurIPS, etc.
Current Research Focus
My current research focuses on pioneering a new generation of multimodal foundation models that integrate generation and understanding within a unified architecture. Specifically:
-
Unified Multimodal Architectures: Designing new-generation frameworks (e.g., discrete diffusion, autoregressive hybrids) that integrate text, image, video, and audio tasks, enabling coherent cross-modal representation, reasoning, and generation. -
Knowledge-Driven and Causality-Aware Modeling: Embedding structured world knowledge, physical realism, and causal reasoning into multimodal models, moving beyond perceptual fidelity toward scientifically grounded and logically consistent outputs. -
General Low-Level Vision Models: Consolidating diverse low-level vision tasks — restoration, enhancement, style transfer, and dense prediction — into a robust multimodal framework, advancing detail recovery, fidelity, and generalization for real-world applications. -
Post-training and Reward Alignment: Developing multimodal alignment and reinforcement learning paradigms, incorporating human preference modeling and expert feedback, to ensure outputs that are not only high-quality and aesthetic but also reliable, interpretable, and scientifically valid.
I am open to collaboration and discussions. Feel free to reach out at liuyihao@pjlab.org.cn or liuyihao14@mails.ucas.ac.cn
news
| May 04, 2026 | I’m glad to share our ICML 2026 work StableI2I, a fidelity-oriented evaluation framework for image-to-image generation. Rather than only asking whether an edited/restored image looks good or follows the instruction, StableI2I focuses on what has been unintentionally changed. It jointly considers the input image, output image, and I2I instruction to diagnose content drift across semantic consistency, structural fidelity, and low-level appearance, covering errors such as object addition/removal/replacement, repainting, misalignment, noise, blur, and color cast. We release StableI2I-Bench, together with StableI2I and StableI2I-PLUS models, to support fine-grained I2I fidelity diagnosis and scoring for more faithful and controllable image editing/restoration systems. [Homepage] [GitHub] [StableI2I-Bench] [StableI2I Model] [StableI2I-PLUS] [Paper]. |
|---|---|
| May 01, 2026 | Five papers accepted by ICML’26. UniPercept was selected as a Spotlight paper. |
| Feb 21, 2026 | Four papers accepted by CVPR’26. |
| Jan 27, 2026 | Four papers accepted by ICLR’26. |
| Dec 30, 2025 | I’m happy to share our new work UniPercept, which tackles a key blind spot of today’s multimodal LLMs: perceptual-level image understanding — how images look and feel to humans — covering aesthetics, quality, structure, and texture. Our release includes UniPercept-Bench, a unified benchmark spanning IAA/IQA/ISTA and supporting both Visual Rating (VR) and Visual Question Answering (VQA) evaluations. We also introduce the UniPercept baseline model to generalize across VR and VQA settings. Beyond benchmarking, UniPercept can be used as a reward model for post-training text-to-image systems and as a perceptual diagnostic tool for analyzing model outputs and datasets. [Homepage] [GitHub] [ UniPercept-Bench] [ UniPercept Model] [Paper]. |
| Oct 21, 2025 | We present PICABench, a new benchmark and evaluation protocol for assessing physical realism in image editing — an often overlooked dimension in current generative models. PICABench systematically evaluates the physical consequences across eight sub-dimensions spanning optics, mechanics, and state transitions, with a reliable PICAEval protocol combining VLM-as-a-judge and region-level human annotations. We also build PICA-100K, a dataset for learning physics from videos. Evaluations show that physical realism remains a major challenge. PICABench aims to drive the next wave of physics-aware, causally consistent image editing. [Homepage] [GitHub] [ PICABench Dataset] [ PICA-100K Dataset] [Paper]. |
| Sep 10, 2025 | We are excited to announce Lumina-DiMOO, our latest unified multimodal generation and understanding model built upon an advanced discrete diffusion architecture. This framework demonstrates the strong potential of multimodal diffusion large language models (dLLM) to unify diverse tasks within a single, streamlined architecture, while delivering state-of-the-art performance that surpasses many existing unified models. Learn more and explore resources: [Homepage] [GitHub] [HuggingFace]. |
| Sep 01, 2025 | We introduce ArtiMuse, a multimodal large language model (MLLM) for professional aesthetic understanding, which is trained on ArtiMuse-10K, a meticulously curated, expert-annotated dataset. ArtiMuse-10K systematically defines eight explainable and fine-grained aesthetic attributes (e.g., Composition & Design, Visual Elements & Structure), with a wide coverage of diverse visual domains, including graphic design, 3D design, AIGC-generated images, photography, and painting & calligraphy. [Paper] [Homepage] [GitHub] [Online Demo v1.0] Note: ArtiMuse was officially released at WAIC 2025, in the forum “Evolving with AI: The Iteration and Resilience of Artistic Creativity”. |
selected publications
- ICML
 UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and TexturearXiv preprint arXiv:2512.21675, 2025
UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and TexturearXiv preprint arXiv:2512.21675, 2025 - ICLR
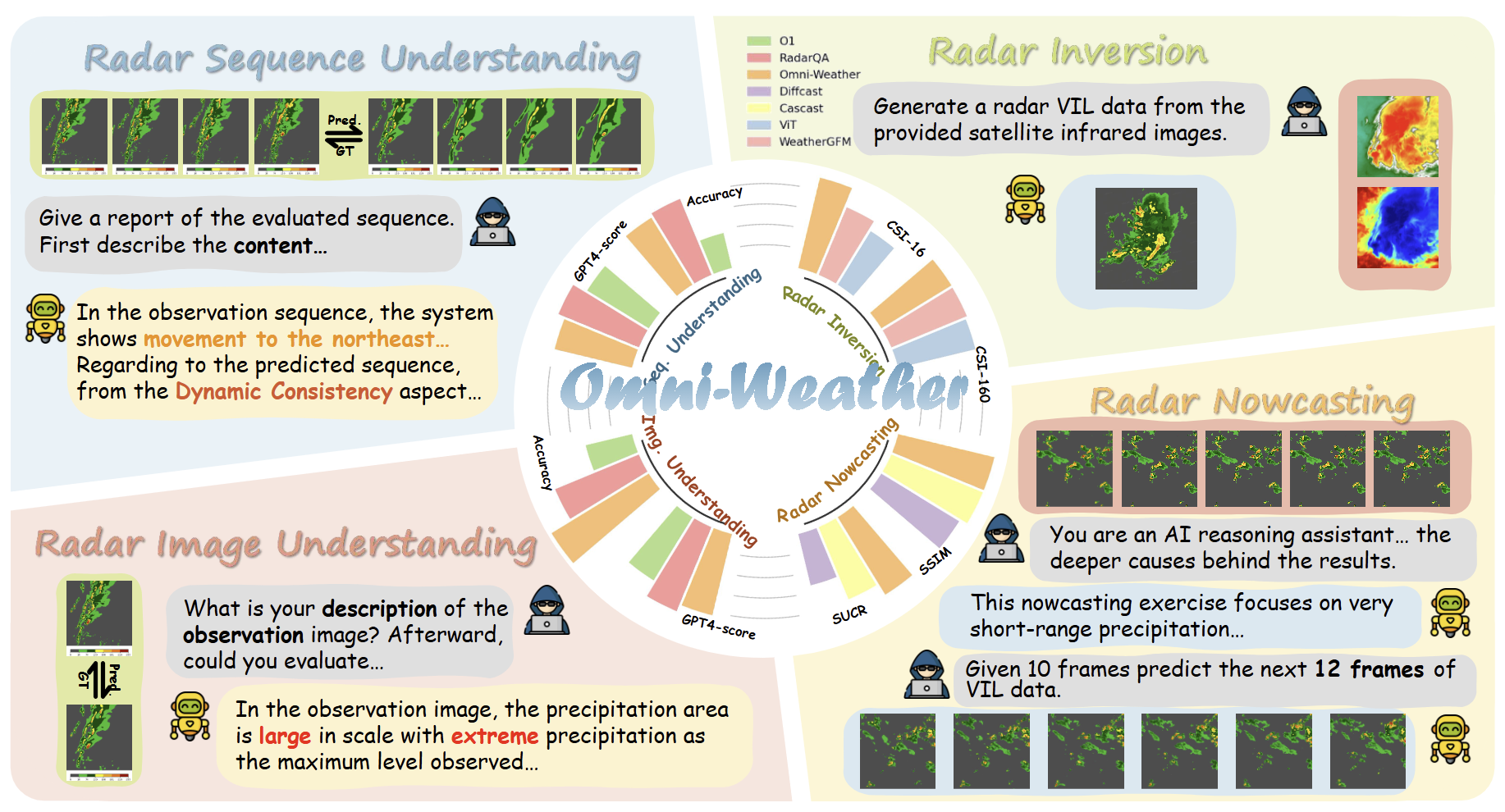 Omni-Weather: Unified Multimodal Foundation Model for Weather Generation and UnderstandingarXiv preprint arXiv:2512.21643, 2025
Omni-Weather: Unified Multimodal Foundation Model for Weather Generation and UnderstandingarXiv preprint arXiv:2512.21643, 2025 - ICLR
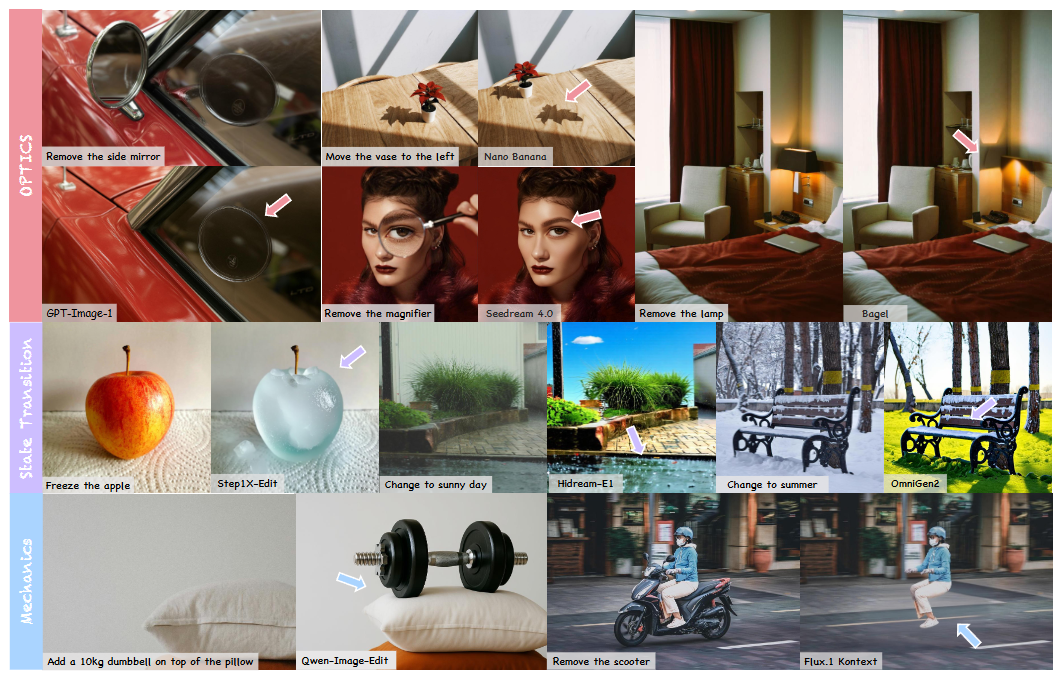 PICABench: How Far Are We from Physically Realistic Image Editing?arXiv preprint arXiv:2510.17681, 2025
PICABench: How Far Are We from Physically Realistic Image Editing?arXiv preprint arXiv:2510.17681, 2025 - CVPR
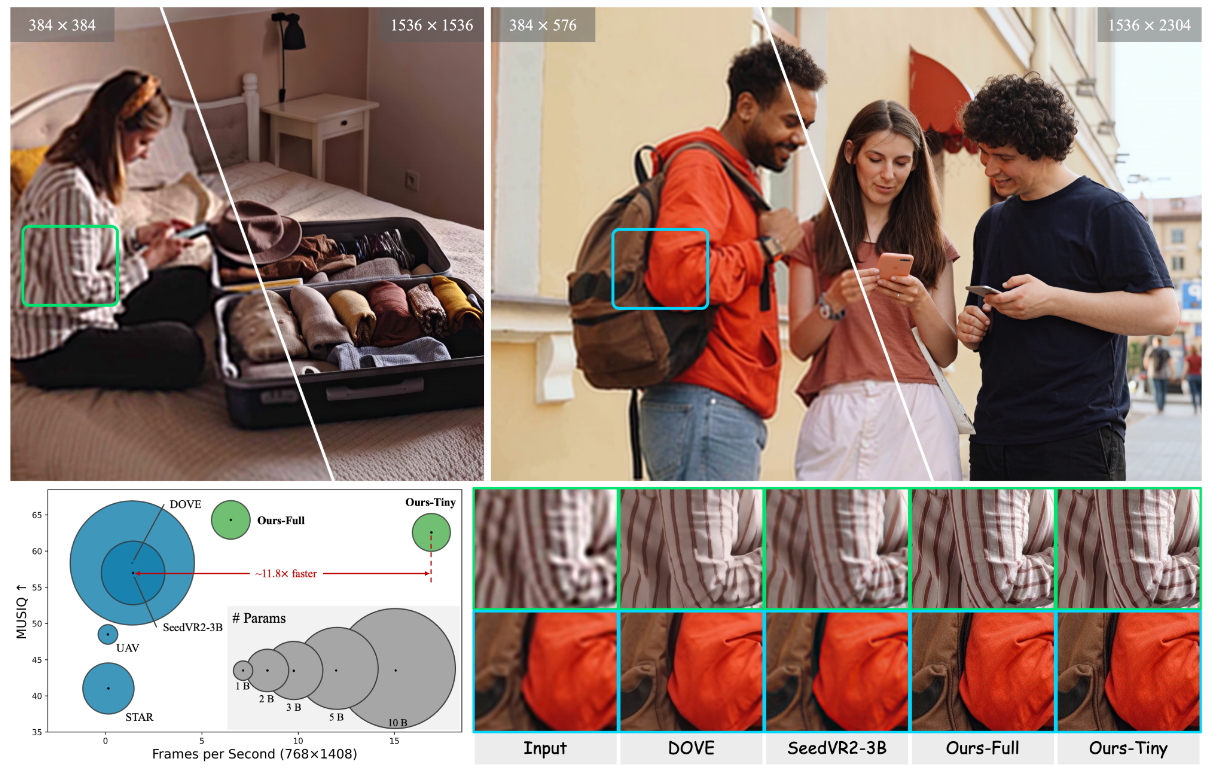 FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-ResolutionarXiv preprint arXiv:2510.12747, 2025
FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-ResolutionarXiv preprint arXiv:2510.12747, 2025 - ICLR
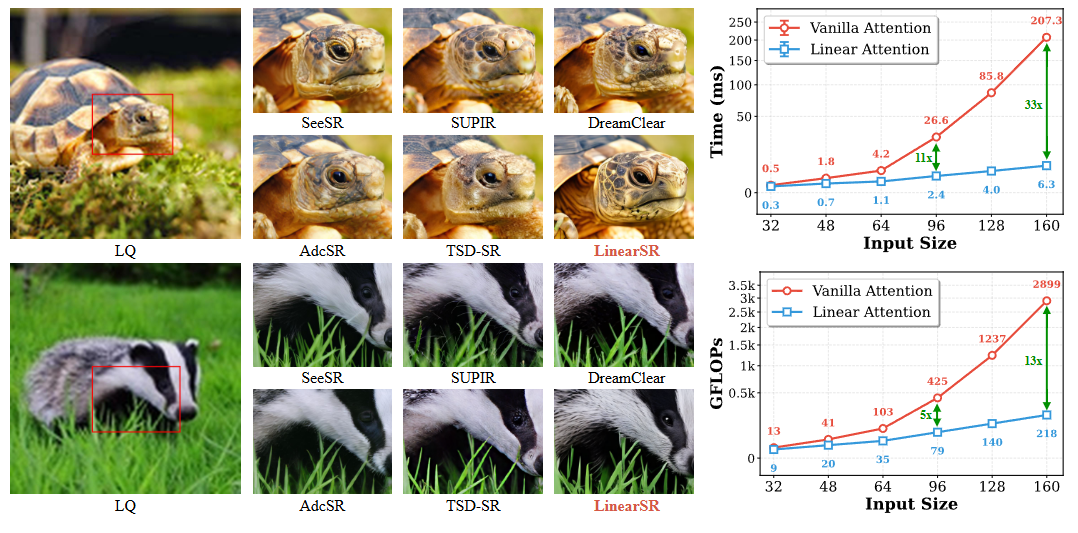 LinearSR: Unlocking Linear Attention for Stable and Efficient Image Super-ResolutionarXiv preprint arXiv:2510.08771, 2025
LinearSR: Unlocking Linear Attention for Stable and Efficient Image Super-ResolutionarXiv preprint arXiv:2510.08771, 2025 - arXiv
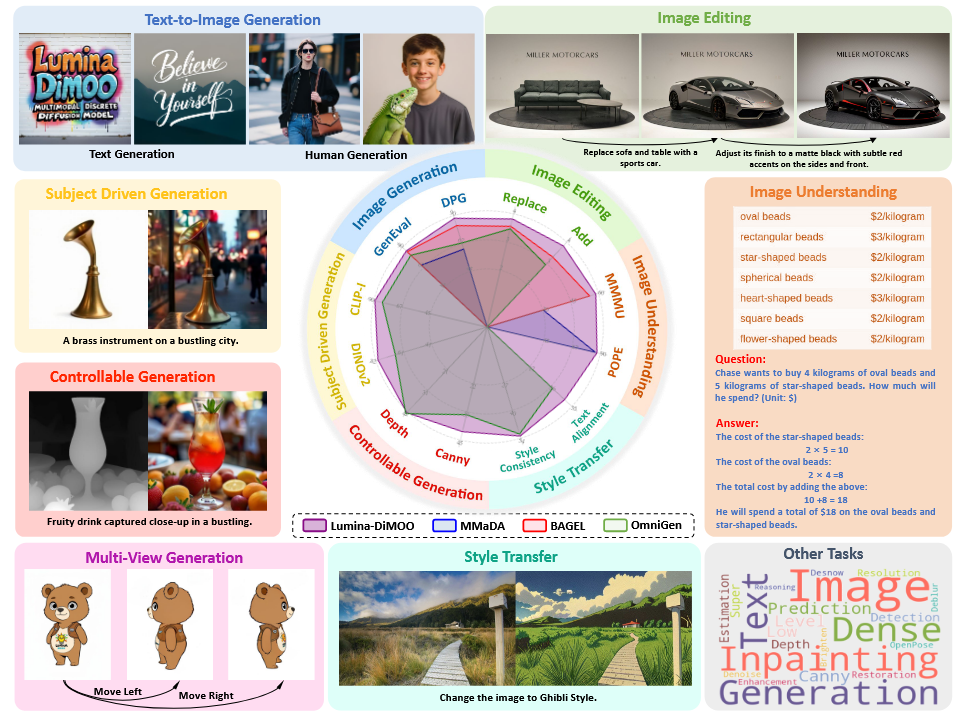 Lumina-dimoo: An omni diffusion large language model for multi-modal generation and understandingarXiv preprint arXiv:2510.06308, 2025
Lumina-dimoo: An omni diffusion large language model for multi-modal generation and understandingarXiv preprint arXiv:2510.06308, 2025 - CVPR
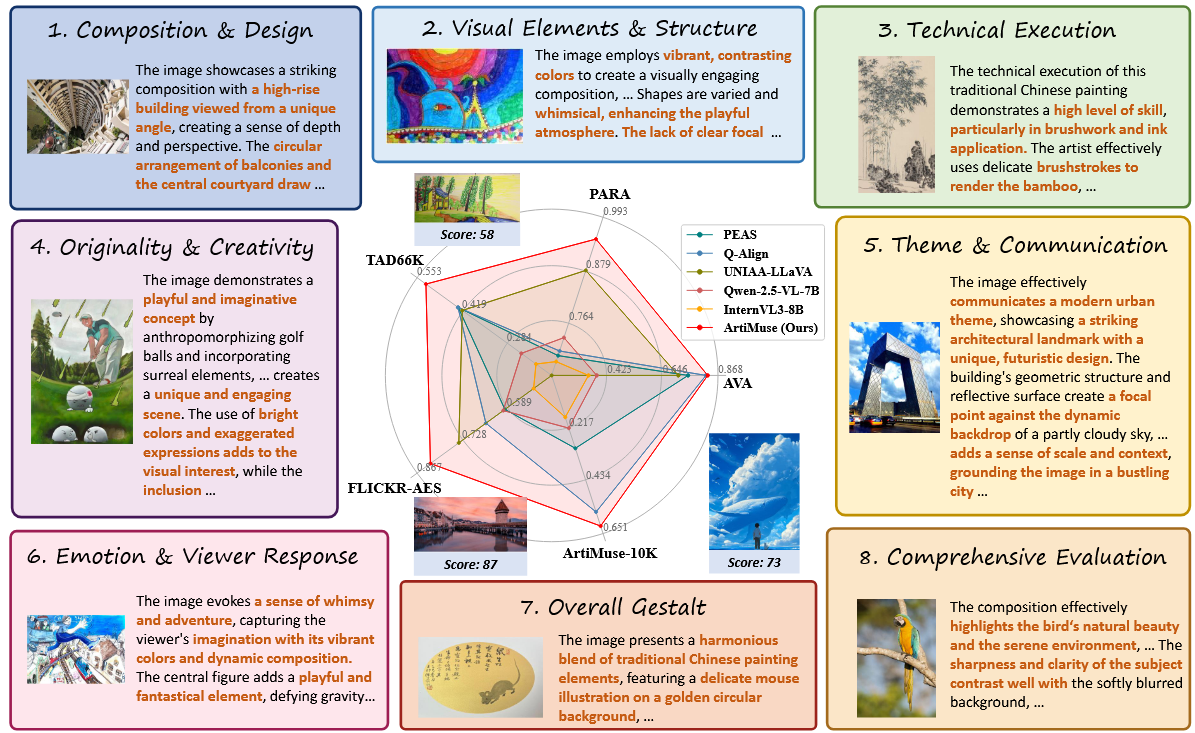 Artimuse: Fine-grained image aesthetics assessment with joint scoring and expert-level understandingarXiv preprint arXiv:2507.14533, 2025
Artimuse: Fine-grained image aesthetics assessment with joint scoring and expert-level understandingarXiv preprint arXiv:2507.14533, 2025 - arXiv
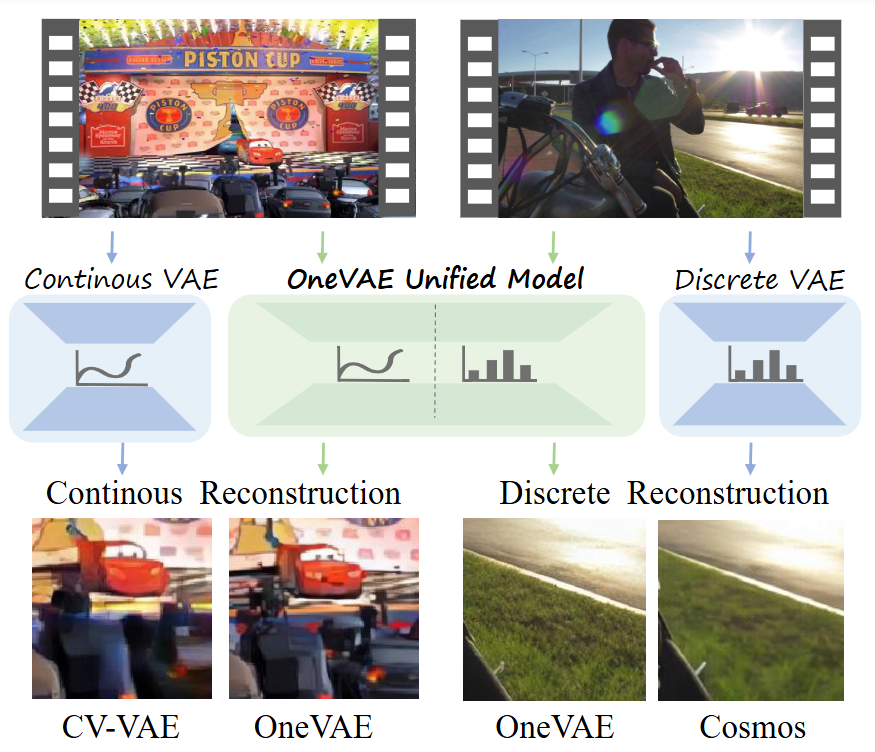 OneVAE: Joint Discrete and Continuous Optimization Helps Discrete Video VAE Train BetterarXiv preprint arXiv:2508.09857, 2025
OneVAE: Joint Discrete and Continuous Optimization Helps Discrete Video VAE Train BetterarXiv preprint arXiv:2508.09857, 2025 - arXiv
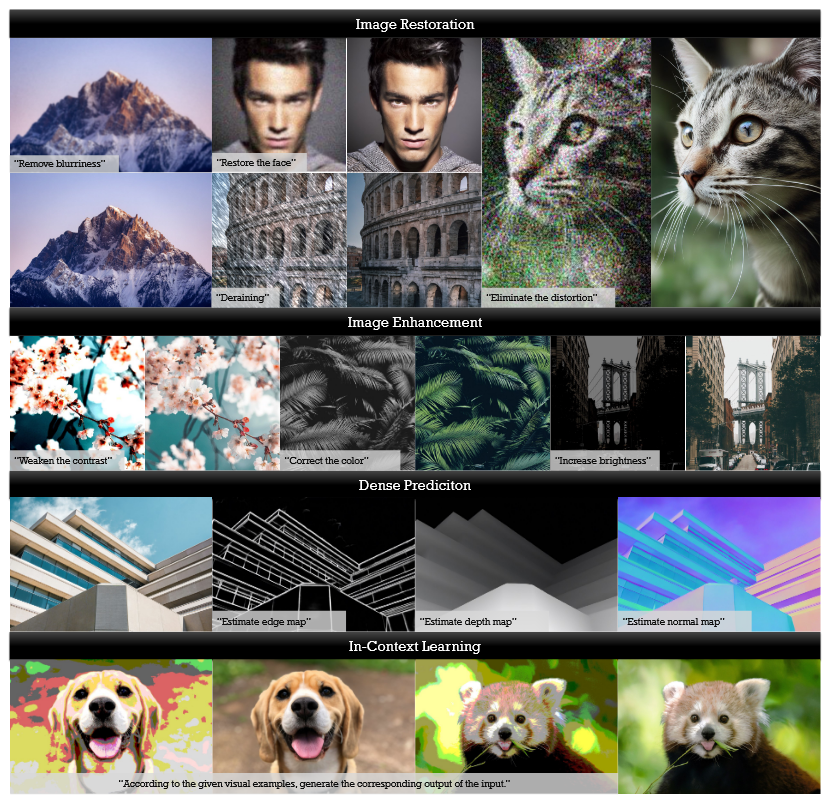 Lumina-omnilv: A unified multimodal framework for general low-level visionarXiv preprint arXiv:2504.04903, 2025
Lumina-omnilv: A unified multimodal framework for general low-level visionarXiv preprint arXiv:2504.04903, 2025 - ICCV
 DiffVSR: Revealing an Effective Recipe for Taming Robust Video Super-Resolution Against Complex DegradationsarXiv preprint arXiv:2501.10110, 2025
DiffVSR: Revealing an Effective Recipe for Taming Robust Video Super-Resolution Against Complex DegradationsarXiv preprint arXiv:2501.10110, 2025 - TIP
 Learning to see low-light images via feature domain adaptationIEEE Transactions on Image Processing, 2025
Learning to see low-light images via feature domain adaptationIEEE Transactions on Image Processing, 2025 - ECCV
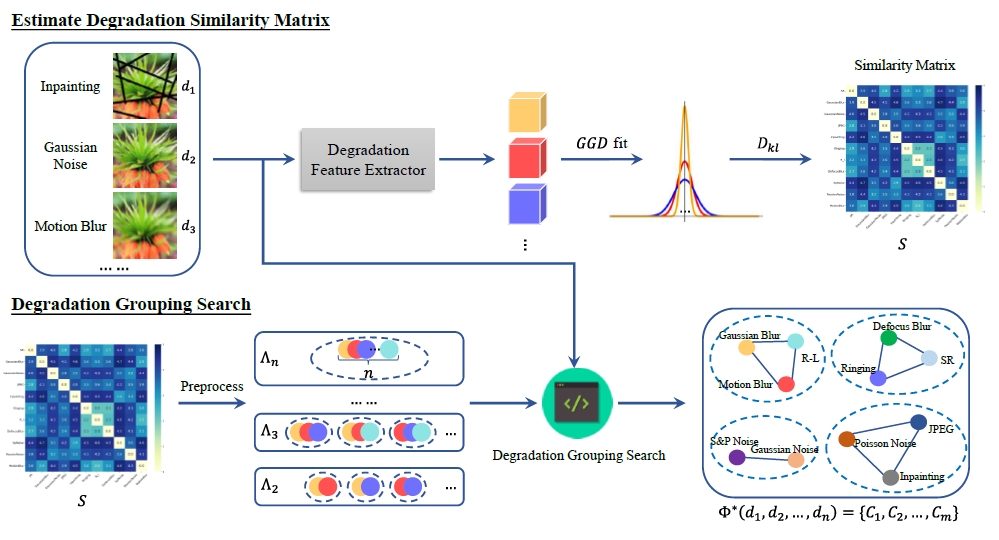 GRIDS: Grouped Multiple-Degradation Restoration with Image Degradation SimilarityIn European Conference on Computer Vision, 2024
GRIDS: Grouped Multiple-Degradation Restoration with Image Degradation SimilarityIn European Conference on Computer Vision, 2024 - ECCV
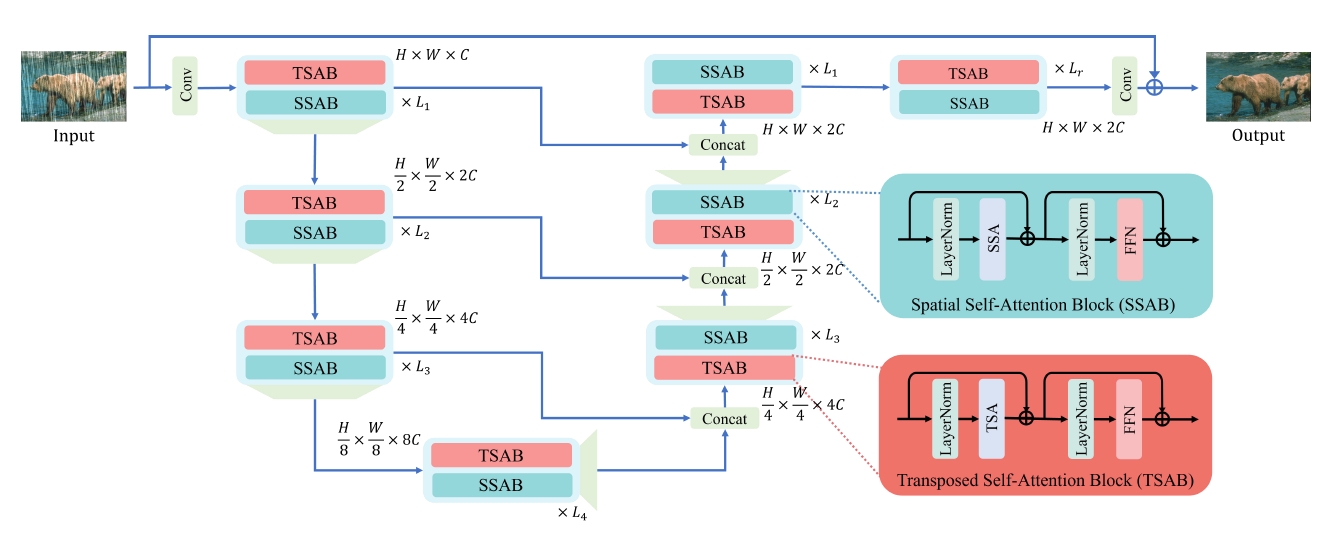 A Comparative Study of Image Restoration Networks for General Backbone Network DesignIn European Conference on Computer Vision, 2024
A Comparative Study of Image Restoration Networks for General Backbone Network DesignIn European Conference on Computer Vision, 2024 - ICML
 Unifying Image Processing as Visual Prompting Question AnsweringIn Proceedings of the 41st International Conference on Machine Learning (ICML), 2024
Unifying Image Processing as Visual Prompting Question AnsweringIn Proceedings of the 41st International Conference on Machine Learning (ICML), 2024 - ACM MM
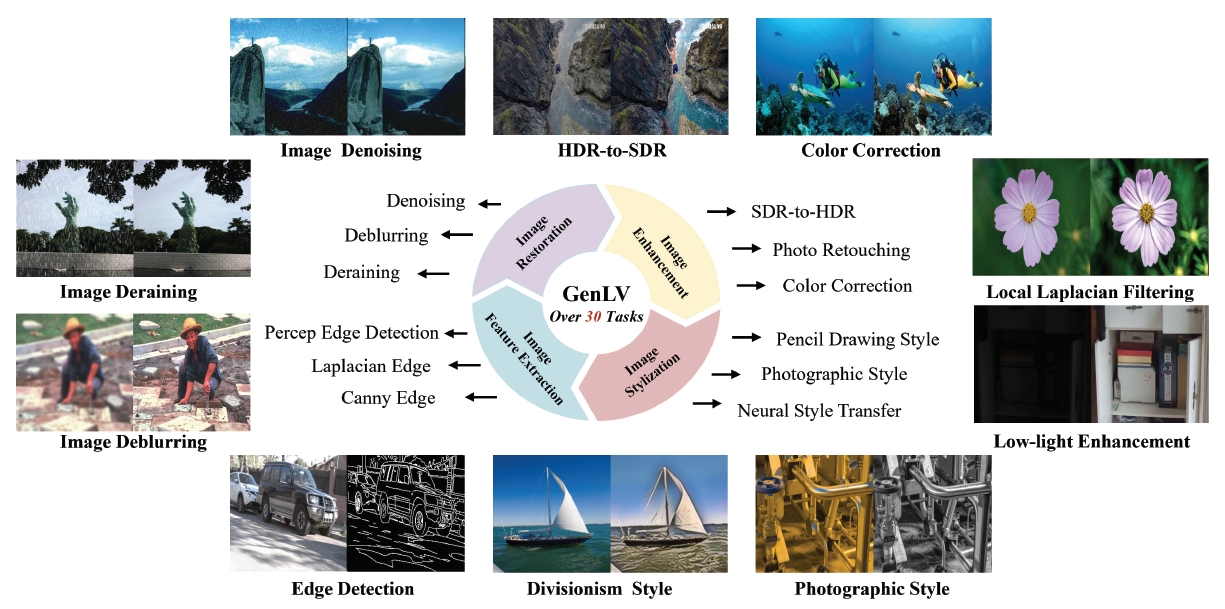 Learning A Low-Level Vision Generalist via Visual Task PromptIn Proceedings of the 32nd ACM International Conference on Multimedia, 2024
Learning A Low-Level Vision Generalist via Visual Task PromptIn Proceedings of the 32nd ACM International Conference on Multimedia, 2024 - CVMJ
 Temporally Consistent Video Colorization with Deep Feature Propagation and Self-Regularization LearningComputational Visual Media, 2024
Temporally Consistent Video Colorization with Deep Feature Propagation and Self-Regularization LearningComputational Visual Media, 2024 - CVPR
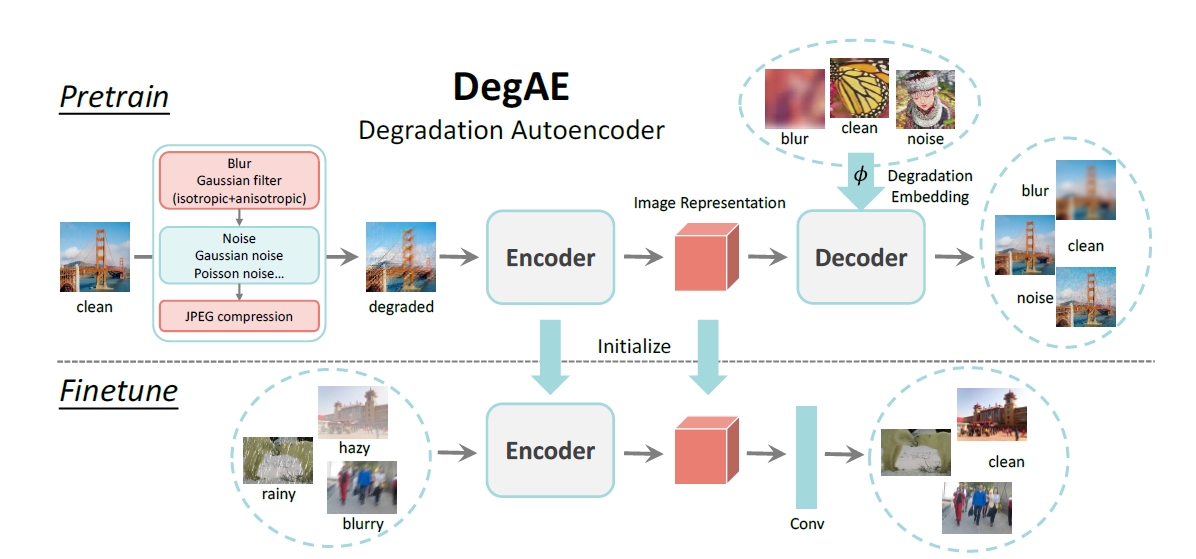 DegAE: A New Pretraining Paradigm for Low-Level VisionIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
DegAE: A New Pretraining Paradigm for Low-Level VisionIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023 - TPAMI
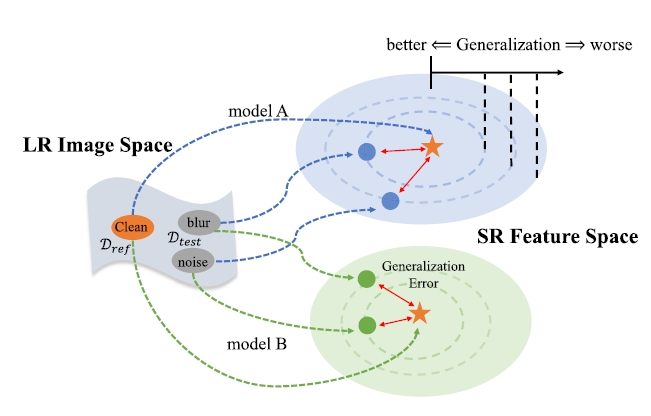 Evaluating the Generalization Ability of Super-Resolution NetworksIEEE Transactions on pattern analysis and machine intelligence, 2023
Evaluating the Generalization Ability of Super-Resolution NetworksIEEE Transactions on pattern analysis and machine intelligence, 2023 - CVPR
 Masked Image Training for Generalizable Deep Image DenoisingIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
Masked Image Training for Generalizable Deep Image DenoisingIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023 - TPAMI
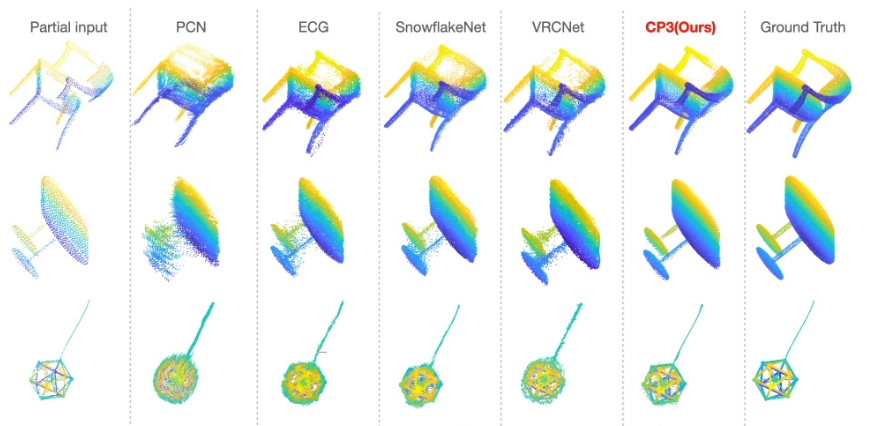 CP3: Unifying Point Cloud Completion by Pretrain-Prompt-Predict ParadigmIEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
CP3: Unifying Point Cloud Completion by Pretrain-Prompt-Predict ParadigmIEEE Transactions on Pattern Analysis and Machine Intelligence, 2023 - TMM
 Very Lightweight Photo Retouching Network with Conditional Sequential ModulationIEEE Transactions on Multimedia, 2022
Very Lightweight Photo Retouching Network with Conditional Sequential ModulationIEEE Transactions on Multimedia, 2022 - TPAMI
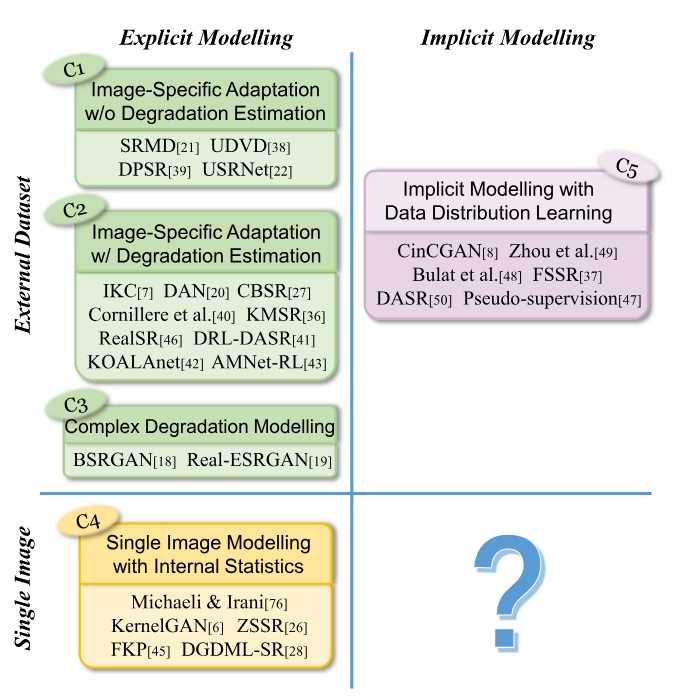 Blind Image Super-Resolution: A Survey and BeyondIEEE transactions on pattern analysis and machine intelligence, 2022
Blind Image Super-Resolution: A Survey and BeyondIEEE transactions on pattern analysis and machine intelligence, 2022 - TPAMI
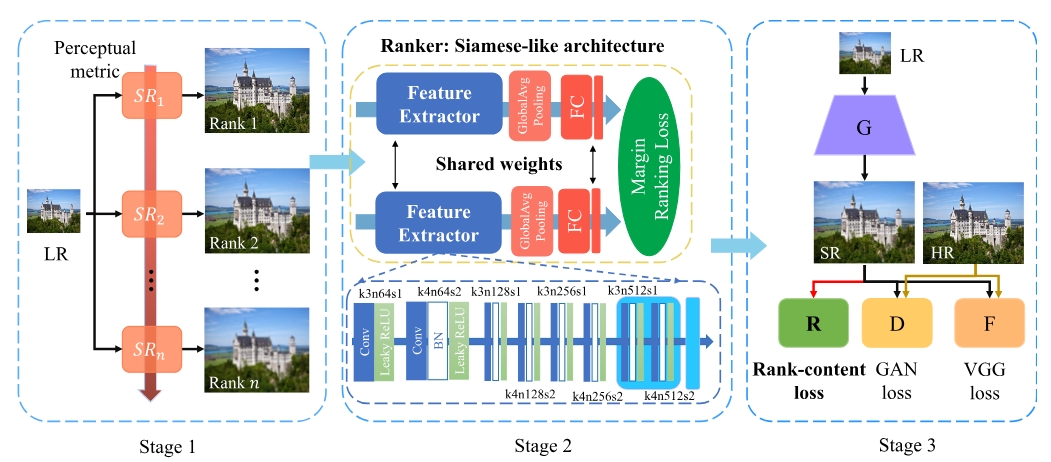 RankSRGAN: Super Resolution Generative Adversarial Networks with Learning to RankIEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
RankSRGAN: Super Resolution Generative Adversarial Networks with Learning to RankIEEE Transactions on Pattern Analysis and Machine Intelligence, 2021 - TPAMI
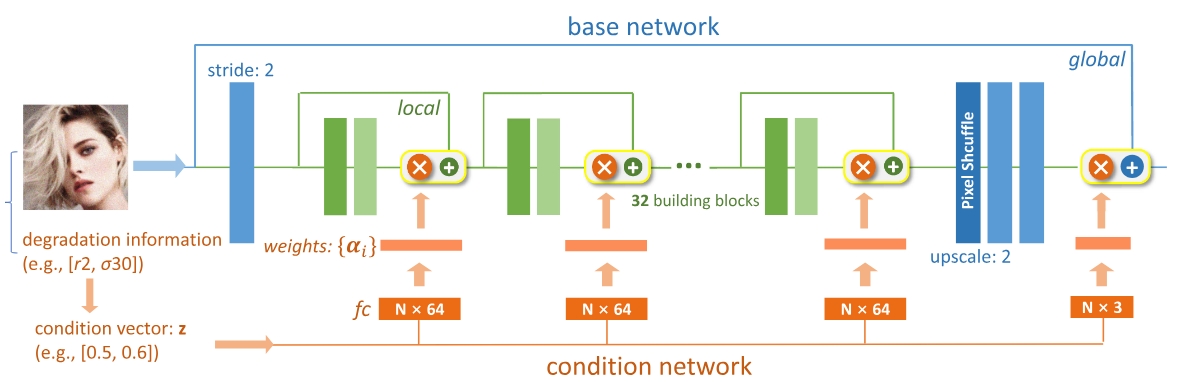 Interactive Multi-Dimension Modulation for Image RestorationIEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
Interactive Multi-Dimension Modulation for Image RestorationIEEE Transactions on Pattern Analysis and Machine Intelligence, 2021 - ICCV
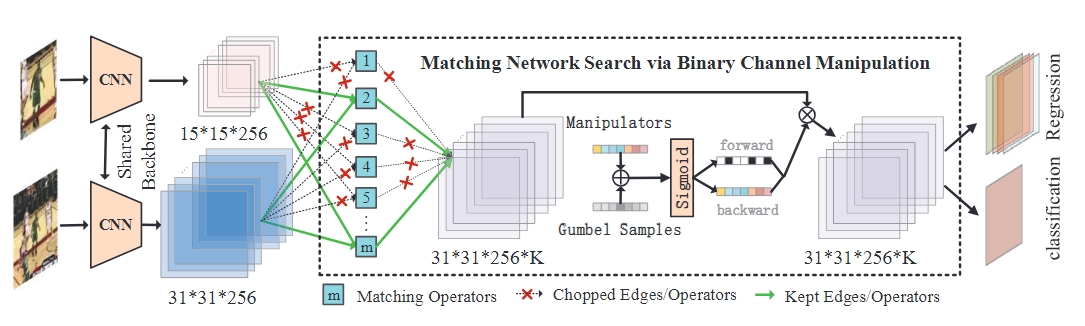 Learn to Match: Automatic Matching Network Design for Visual TrackingIn International Conference on Computer Vision (ICCV), 2021
Learn to Match: Automatic Matching Network Design for Visual TrackingIn International Conference on Computer Vision (ICCV), 2021 - arXiv
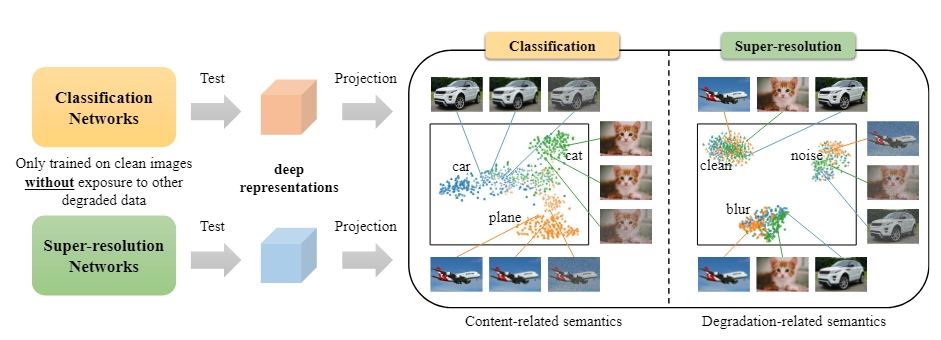 Discovering" Semantics" in Super-Resolution NetworksarXiv preprint arXiv:2108.00406, 2021
Discovering" Semantics" in Super-Resolution NetworksarXiv preprint arXiv:2108.00406, 2021 - AAAI
 FD-GAN: Generative Adversarial Networks with Fusion-Discriminator for Single Image DehazingIn Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020
FD-GAN: Generative Adversarial Networks with Fusion-Discriminator for Single Image DehazingIn Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020 - ECCV
 Conditional Sequential Modulation for Efficient Global Image RetouchingIn European Conference on Computer Vision (ECCV), 2020
Conditional Sequential Modulation for Efficient Global Image RetouchingIn European Conference on Computer Vision (ECCV), 2020 - ECCVW
 Enhanced Quadratic Video InterpolationIn European Conference on Computer Vision (ECCV) Workshops, 2020
Enhanced Quadratic Video InterpolationIn European Conference on Computer Vision (ECCV) Workshops, 2020 - ICCVRankSRGAN: Generative Adversarial Networks with Ranker for Image Super-ResolutionIn International Conference on Computer Vision (ICCV), 2019
- ECCVWESRGAN: Enhanced Super-Resolution Generative Adversarial NetworksIn Proceedings of the European conference on computer vision (ECCV) workshops, 2018




























